
Data Sintetis: Kunci Membuka Potensi AI di Era Privasi
Di era digital yang didorong oleh data, kecerdasan buatan (AI) dan machine learning (ML) telah menjadi kekuatan transformatif di berbagai industri. Dari diagnosis medis yang lebih akurat hingga kendaraan otonom dan layanan keuangan yang dipersonalisasi, potensi AI tampaknya tak terbatas. Namun, salah satu hambatan terbesar dalam pengembangan dan penerapan AI adalah ketersediaan data berkualitas tinggi dan representatif.
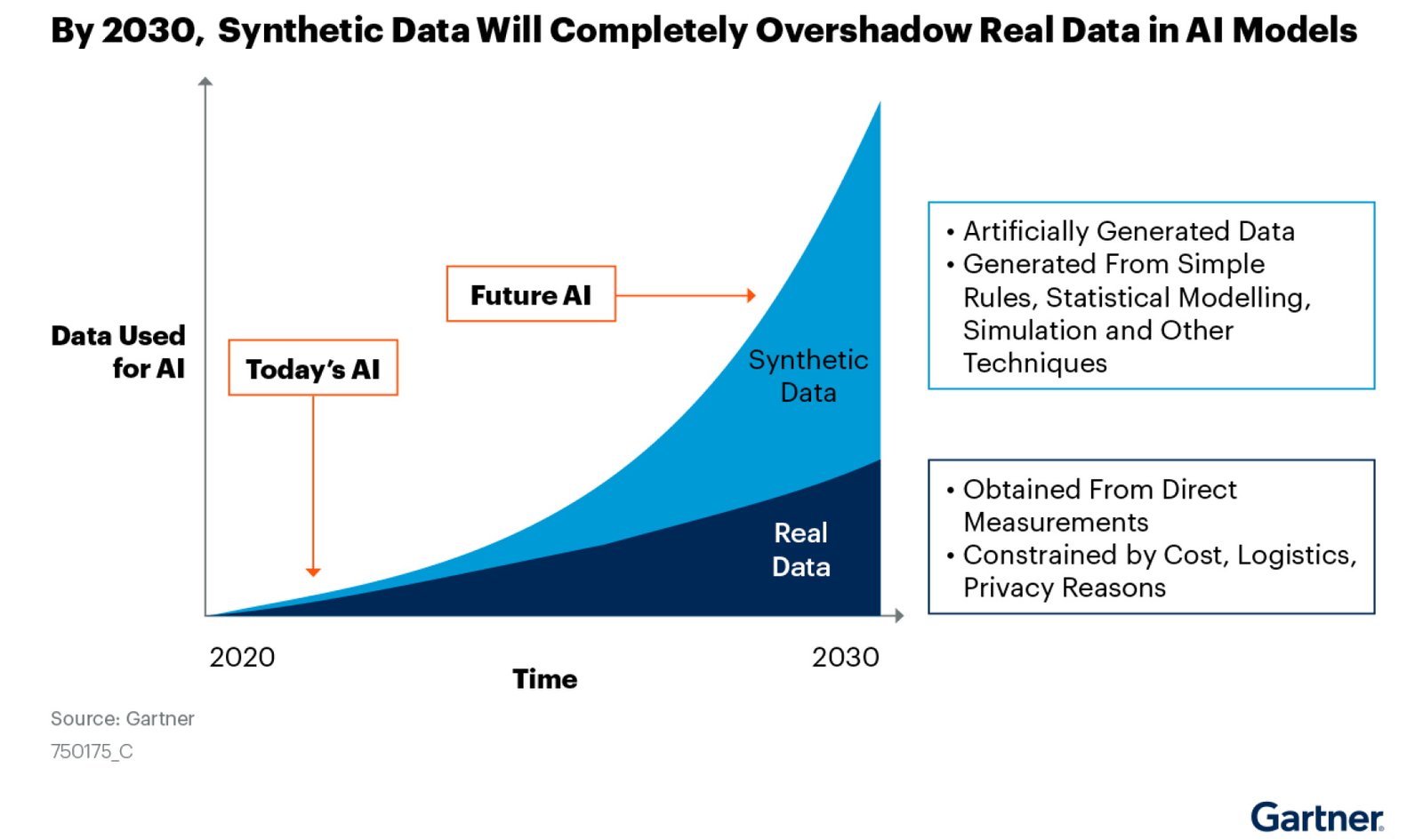
Data yang dibutuhkan untuk melatih model AI seringkali sensitif, rahasia, atau sulit diperoleh. Regulasi privasi yang ketat, seperti GDPR dan CCPA, semakin membatasi akses ke data pribadi. Di sinilah data sintetis hadir sebagai solusi inovatif.
Apa itu Data Sintetis?
Data sintetis adalah data buatan yang dihasilkan secara artifisial, bukan dikumpulkan dari peristiwa atau pengukuran dunia nyata. Data ini dirancang untuk meniru karakteristik statistik dan pola data asli, tanpa mengungkapkan informasi pribadi atau rahasia yang mendasarinya.
Dengan kata lain, data sintetis adalah replika digital dari data nyata. Ia memiliki struktur, format, dan properti statistik yang serupa, tetapi tidak terkait langsung dengan individu atau entitas tertentu.
Bagaimana Data Sintetis Dibuat?
Ada berbagai teknik untuk menghasilkan data sintetis, tergantung pada jenis data dan tujuan penggunaannya. Beberapa metode umum meliputi:
- Pemodelan Statistik: Metode ini menggunakan model statistik untuk menghasilkan data yang mengikuti distribusi dan korelasi yang sama dengan data asli. Misalnya, jika data asli menunjukkan hubungan antara usia dan pendapatan, model statistik akan menghasilkan data sintetis dengan hubungan serupa.
- Generative Adversarial Networks (GANs): GANs adalah jenis jaringan saraf yang terdiri dari dua bagian: generator dan diskriminator. Generator mencoba menghasilkan data sintetis yang terlihat realistis, sementara diskriminator mencoba membedakan antara data sintetis dan data asli. Melalui proses pelatihan adversarial, GANs dapat menghasilkan data sintetis yang sangat mirip dengan data asli.
- Variational Autoencoders (VAEs): VAEs adalah jenis jaringan saraf lainnya yang digunakan untuk menghasilkan data sintetis. VAEs belajar representasi terkompresi dari data asli, dan kemudian menggunakan representasi ini untuk menghasilkan data sintetis baru.
- Simulasi: Dalam beberapa kasus, data sintetis dapat dihasilkan melalui simulasi. Misalnya, dalam pengembangan kendaraan otonom, data sintetis dapat dihasilkan dengan mensimulasikan berbagai skenario mengemudi.
Manfaat Data Sintetis
Data sintetis menawarkan sejumlah manfaat signifikan dibandingkan data asli:
- Privasi: Data sintetis tidak mengandung informasi pribadi atau rahasia, sehingga dapat digunakan tanpa melanggar regulasi privasi.
- Ketersediaan: Data sintetis dapat dihasilkan sesuai permintaan, mengatasi masalah kelangkaan data yang sering dihadapi dalam pengembangan AI.
- Aksesibilitas: Data sintetis dapat dibagikan dan diakses dengan mudah, memfasilitasi kolaborasi dan inovasi.
- Biaya: Data sintetis seringkali lebih murah untuk dihasilkan daripada mengumpulkan data asli.
- Kontrol: Data sintetis memungkinkan pengembang untuk mengontrol karakteristik dan distribusi data, memastikan bahwa model AI dilatih dengan data yang representatif dan seimbang.
- Augmentasi Data: Data sintetis dapat digunakan untuk menambah data asli, meningkatkan kinerja dan generalisasi model AI.
- Uji Coba dan Validasi: Data sintetis dapat digunakan untuk menguji dan memvalidasi model AI dalam lingkungan yang aman dan terkendali.
Aplikasi Data Sintetis
Data sintetis memiliki berbagai aplikasi di berbagai industri:
- Kesehatan: Data sintetis dapat digunakan untuk melatih model AI untuk diagnosis penyakit, pengembangan obat, dan personalisasi perawatan, tanpa mengungkapkan informasi pasien yang sensitif.
- Keuangan: Data sintetis dapat digunakan untuk mendeteksi penipuan, menilai risiko kredit, dan mengembangkan produk keuangan baru, tanpa melanggar privasi pelanggan.
- Otomotif: Data sintetis dapat digunakan untuk melatih kendaraan otonom dalam berbagai skenario mengemudi, termasuk situasi berbahaya yang sulit direplikasi di dunia nyata.
- Ritel: Data sintetis dapat digunakan untuk personalisasi pengalaman pelanggan, mengoptimalkan rantai pasokan, dan memprediksi permintaan, tanpa mengungkapkan informasi pribadi pelanggan.
- Manufaktur: Data sintetis dapat digunakan untuk mengoptimalkan proses produksi, memprediksi kegagalan peralatan, dan meningkatkan kualitas produk.
- Asuransi: Data sintetis dapat digunakan untuk menilai risiko, mendeteksi penipuan klaim, dan mengembangkan produk asuransi baru.
Tantangan dan Pertimbangan
Meskipun data sintetis menawarkan banyak manfaat, ada juga beberapa tantangan dan pertimbangan yang perlu diperhatikan:
- Kualitas Data: Kualitas data sintetis sangat penting untuk memastikan bahwa model AI yang dilatih dengan data tersebut memiliki kinerja yang baik. Data sintetis harus representatif dari data asli dan mempertahankan karakteristik statistik yang relevan.
- Bias: Data sintetis dapat mewarisi bias dari data asli atau dari proses pembuatan data sintetis. Penting untuk mengidentifikasi dan mengurangi bias dalam data sintetis untuk memastikan bahwa model AI yang dilatih dengan data tersebut adil dan tidak diskriminatif.
- Validasi: Penting untuk memvalidasi data sintetis untuk memastikan bahwa data tersebut memenuhi persyaratan aplikasi yang dimaksud. Validasi dapat dilakukan dengan membandingkan kinerja model AI yang dilatih dengan data sintetis dengan kinerja model AI yang dilatih dengan data asli.
- Keamanan: Meskipun data sintetis tidak mengandung informasi pribadi atau rahasia, data tersebut tetap perlu diamankan untuk mencegah akses yang tidak sah.
- Regulasi: Regulasi privasi yang berlaku dapat mempengaruhi penggunaan data sintetis. Penting untuk memahami dan mematuhi regulasi yang relevan.
Masa Depan Data Sintetis
Data sintetis memiliki potensi besar untuk merevolusi pengembangan dan penerapan AI. Seiring dengan kemajuan teknologi, kita dapat mengharapkan data sintetis menjadi lebih realistis, akurat, dan mudah diakses.
Beberapa tren utama yang membentuk masa depan data sintetis meliputi:
- Peningkatan Kualitas: Algoritma dan teknik untuk menghasilkan data sintetis terus berkembang, menghasilkan data yang lebih berkualitas dan representatif.
- Otomatisasi: Proses pembuatan data sintetis semakin otomatis, memungkinkan pengguna untuk menghasilkan data sintetis dengan mudah dan cepat.
- Spesialisasi: Solusi data sintetis yang disesuaikan dengan kebutuhan spesifik industri dan aplikasi semakin banyak tersedia.
- Integrasi: Data sintetis semakin terintegrasi dengan platform dan alat pengembangan AI, memfasilitasi penggunaan data sintetis dalam alur kerja AI.
- Standarisasi: Upaya untuk mengembangkan standar dan praktik terbaik untuk data sintetis semakin meningkat, meningkatkan kualitas dan interoperabilitas data sintetis.
Kesimpulan
Data sintetis adalah alat yang ampuh untuk mengatasi tantangan privasi dan ketersediaan data dalam pengembangan AI. Dengan menghasilkan data buatan yang meniru karakteristik data asli, data sintetis memungkinkan organisasi untuk melatih model AI yang akurat dan efektif tanpa mengungkapkan informasi sensitif.
Seiring dengan kemajuan teknologi dan meningkatnya kesadaran akan manfaat data sintetis, kita dapat mengharapkan data sintetis untuk memainkan peran yang semakin penting dalam masa depan AI. Dengan mengatasi hambatan data, data sintetis membuka potensi AI untuk memecahkan masalah kompleks dan meningkatkan kehidupan kita di berbagai bidang.












