
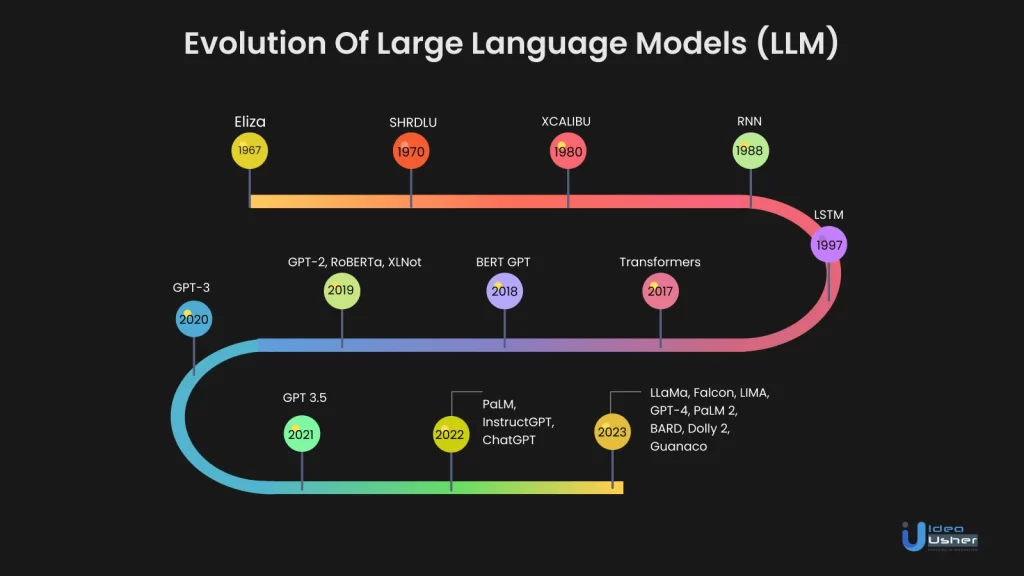
Large Language Models (LLM): Revolusi Kecerdasan Buatan dalam Pengolahan Bahasa Alami
Dalam beberapa tahun terakhir, bidang kecerdasan buatan (AI) telah mengalami kemajuan pesat, terutama dalam pengolahan bahasa alami (NLP). Di antara inovasi-inovasi yang paling menonjol adalah Large Language Models (LLM), sebuah terobosan yang merevolusi cara kita berinteraksi dengan mesin dan memanfaatkan kekuatan bahasa. Artikel ini akan membahas secara mendalam tentang LLM, meliputi definisi, arsitektur, kemampuan, aplikasi, tantangan, dan potensi masa depannya.
Apa itu Large Language Models (LLM)?
Large Language Models (LLM) adalah model AI yang dilatih pada dataset teks yang sangat besar untuk memahami, menghasilkan, dan memanipulasi bahasa manusia. Mereka menggunakan teknik pembelajaran mendalam (deep learning), khususnya arsitektur transformer, untuk mempelajari pola-pola kompleks dalam bahasa dan menghasilkan teks yang koheren, relevan, dan seringkali sulit dibedakan dari tulisan manusia.
Beberapa contoh LLM yang populer meliputi:
- GPT (Generative Pre-trained Transformer) series: Dikembangkan oleh OpenAI, GPT telah mencapai popularitas luas karena kemampuannya menghasilkan teks yang kreatif dan realistis.
- BERT (Bidirectional Encoder Representations from Transformers): Dikembangkan oleh Google, BERT unggul dalam pemahaman konteks bahasa dan tugas-tugas klasifikasi teks.
- LaMDA (Language Model for Dialogue Applications): Dikembangkan oleh Google, LaMDA dirancang khusus untuk percakapan yang alami dan informatif.
- BLOOM (BigScience Large Open-science Open-access Multilingual Language Model): Model open-source yang dikembangkan oleh komunitas riset BigScience, dengan fokus pada kemampuan multibahasa.
Arsitektur Transformer: Jantung dari LLM
Keberhasilan LLM sangat bergantung pada arsitektur transformer, yang diperkenalkan dalam makalah berjudul "Attention is All You Need" pada tahun 2017. Arsitektur ini mengatasi keterbatasan model sekuensial sebelumnya, seperti RNN (Recurrent Neural Networks), dengan memanfaatkan mekanisme perhatian (attention mechanism) untuk menangkap hubungan antar kata dalam kalimat secara paralel.
Arsitektur transformer terdiri dari dua komponen utama:
- Encoder: Memproses input teks dan menghasilkan representasi kontekstual dari setiap kata.
- Decoder: Menggunakan representasi kontekstual dari encoder untuk menghasilkan output teks.
Mekanisme perhatian memungkinkan model untuk fokus pada kata-kata yang paling relevan dalam kalimat saat memproses atau menghasilkan teks. Hal ini sangat penting untuk memahami konteks dan menghasilkan teks yang koheren.
Kemampuan LLM: Lebih dari Sekadar Menghasilkan Teks
LLM memiliki berbagai kemampuan yang melampaui sekadar menghasilkan teks. Beberapa kemampuan utama LLM meliputi:
- Pemahaman Bahasa Alami (NLU): Memahami makna dan konteks teks input, termasuk identifikasi entitas, analisis sentimen, dan inferensi.
- Generasi Bahasa Alami (NLG): Menghasilkan teks yang koheren, relevan, dan gramatikal dengan berbagai gaya dan format.
- Penerjemahan Bahasa: Menerjemahkan teks dari satu bahasa ke bahasa lain dengan akurasi yang tinggi.
- Summarisasi Teks: Merangkum teks panjang menjadi versi yang lebih pendek dan ringkas.
- Jawab Pertanyaan: Menjawab pertanyaan berdasarkan informasi yang terkandung dalam teks atau pengetahuan yang telah dipelajari.
- Pembuatan Kode: Menghasilkan kode program berdasarkan deskripsi bahasa alami.
- Percakapan: Berinteraksi dengan pengguna dalam percakapan yang alami dan informatif.
Aplikasi LLM: Transformasi di Berbagai Industri
Kemampuan LLM yang beragam membuka berbagai aplikasi di berbagai industri, termasuk:
- Layanan Pelanggan: Chatbot yang didukung LLM dapat memberikan dukungan pelanggan 24/7, menjawab pertanyaan, dan menyelesaikan masalah.
- Pemasaran: LLM dapat menghasilkan konten pemasaran yang menarik, seperti iklan, deskripsi produk, dan posting media sosial.
- Penulisan Konten: LLM dapat membantu penulis menghasilkan artikel, blog, dan buku dengan lebih cepat dan efisien.
- Pendidikan: LLM dapat memberikan umpan balik tentang tugas, menjawab pertanyaan siswa, dan menghasilkan materi pembelajaran yang dipersonalisasi.
- Penelitian: LLM dapat membantu peneliti menganalisis data teks, menemukan tren, dan menghasilkan hipotesis.
- Kesehatan: LLM dapat membantu dokter mendiagnosis penyakit, meresepkan obat, dan memberikan informasi kesehatan kepada pasien.
- Hukum: LLM dapat membantu pengacara meneliti kasus, menyusun dokumen hukum, dan memberikan nasihat hukum.
Tantangan dalam Pengembangan dan Penerapan LLM
Meskipun LLM menawarkan potensi yang besar, ada beberapa tantangan yang perlu diatasi dalam pengembangan dan penerapannya:
- Bias: LLM dapat mewarisi bias dari data pelatihan mereka, yang dapat menghasilkan output yang diskriminatif atau tidak adil.
- Hallucination: LLM terkadang dapat menghasilkan informasi yang salah atau tidak akurat, yang disebut "halusinasi."
- Kebutuhan Komputasi: Melatih dan menjalankan LLM membutuhkan sumber daya komputasi yang besar, yang dapat menjadi penghalang bagi banyak organisasi.
- Interpretability: Sulit untuk memahami bagaimana LLM membuat keputusan, yang dapat menjadi masalah dalam aplikasi yang sensitif.
- Keamanan: LLM dapat disalahgunakan untuk menghasilkan konten berbahaya, seperti berita palsu atau ujaran kebencian.
Masa Depan LLM: Menuju Kecerdasan Buatan yang Lebih Cerdas dan Bertanggung Jawab
Masa depan LLM sangat menjanjikan. Kita dapat mengharapkan LLM menjadi lebih cerdas, lebih efisien, dan lebih mudah diakses. Beberapa tren yang mungkin kita lihat di masa depan meliputi:
- Model yang Lebih Besar dan Lebih Cerdas: LLM akan terus berkembang dalam ukuran dan kompleksitas, yang akan meningkatkan kemampuan mereka dalam memahami dan menghasilkan bahasa.
- Pembelajaran Multimodal: LLM akan diintegrasikan dengan modalitas lain, seperti gambar dan audio, untuk menciptakan model yang lebih holistik dan serbaguna.
- Personalisasi: LLM akan dipersonalisasi untuk memenuhi kebutuhan individu, yang akan memungkinkan mereka untuk memberikan pengalaman yang lebih relevan dan efektif.
- Etika dan Tanggung Jawab: Akan ada fokus yang lebih besar pada etika dan tanggung jawab dalam pengembangan dan penerapan LLM, untuk memastikan bahwa mereka digunakan untuk tujuan yang baik dan tidak membahayakan masyarakat.
- Aplikasi yang Lebih Luas: LLM akan diterapkan di lebih banyak industri dan aplikasi, yang akan mengubah cara kita bekerja, belajar, dan berinteraksi dengan dunia di sekitar kita.
Kesimpulan
Large Language Models (LLM) adalah terobosan penting dalam bidang kecerdasan buatan. Mereka memiliki potensi untuk merevolusi cara kita berinteraksi dengan mesin dan memanfaatkan kekuatan bahasa. Meskipun ada beberapa tantangan yang perlu diatasi, masa depan LLM sangat menjanjikan. Dengan pengembangan dan penerapan yang bertanggung jawab, LLM dapat membawa manfaat yang besar bagi masyarakat.
: Revolusi Kecerdasan Buatan dalam Pengolahan Bahasa Alami")











